logstash Docker部署 #
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第6天,点击查看活动详情 (opens new window)
前言 #
大家好,我是小郭,最近在玩 ELK 日志平台,它是 Elastic 公司推出的一整套日志收集、分析和展示的解决方案。
只有学习了,操作了才能算真正的学会使用了,虽然看起来简单,但是里面的流程步骤还是很多的,将步骤和遇到的问
题记录和总结下,今天主要分享下在Docker环境下部署 logstash 日志收集工具。
# 从零到一搭建ELK日志,在Docker环境下部署 Elasticsearch 数据库 (opens new window)
# 从零到一搭建ELK日志,在Docker环境下部署 Kibana 可视化工具 (opens new window)
# 从零到一搭建ELK日志,在Docker环境下部署 Filebeat 日志收集工具 (opens new window)
什么是 logstash? #
Logstash是具有实时流水线能力的开源的数据收集引擎。Logstash可以动态统一不同来源的数据,并将数据标准化到您选择的目标输出。它提供了大量插件,可帮助我们解析,丰富,转换和缓冲任何类型的数据。
工作方式 #
管道(Logstash Pipeline)是Logstash中独立的运行单元,每个管道都包含两个必须的元素输入(input)和输出(output),和一个可选的元素过滤器(filter),事件处理管道负责协调它们的执行。
输入和输出支持编解码器,使您可以在数据进入或退出管道时对其进行编码或解码,而不必使用单独的过滤器。如:json、multiline等
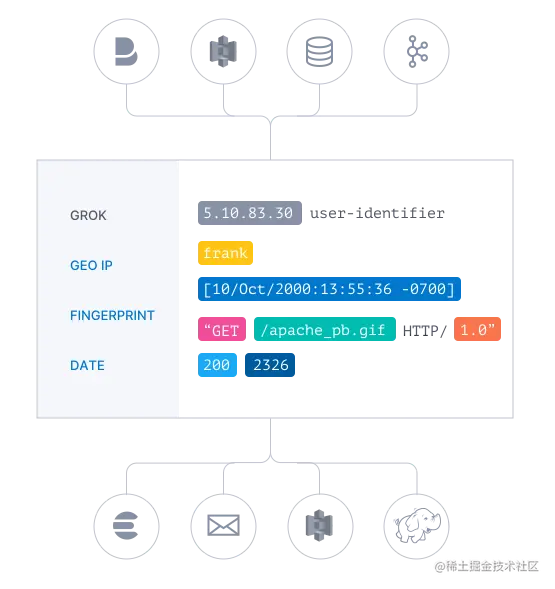
inputs(输入阶段): #
Logstash 支持各种输入选择,可以同时从众多常用来源捕捉事件。
包括:file、kafka、beats等
filters(筛选阶段): #
数据从源传输到存储库的过程中,Logstash 筛选器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便进行更强大的分析和实现商业价值。
包括:
利用 Grok 从非结构化数据中派生出结构
简化整体处理,不受数据源、格式或架构的影响等
outputs(输出阶段): #
将事件数据发送到特定的目的地,完成了所以输出处理,改事件就完成了执行。
如:elasticsearch、file、redis等
Codecs(解码器): #
基本上是流过滤器,作为输入和输出的一部分进行操作,可以轻松地将消息的传输与序列化过程分开。
扩展 #
Logstash 采用可插拔框架,拥有 200 多个插件。您可以将不同的输入选择、筛选器和输出选择混合搭配、精心安排,让它们在管道中和谐地运行。
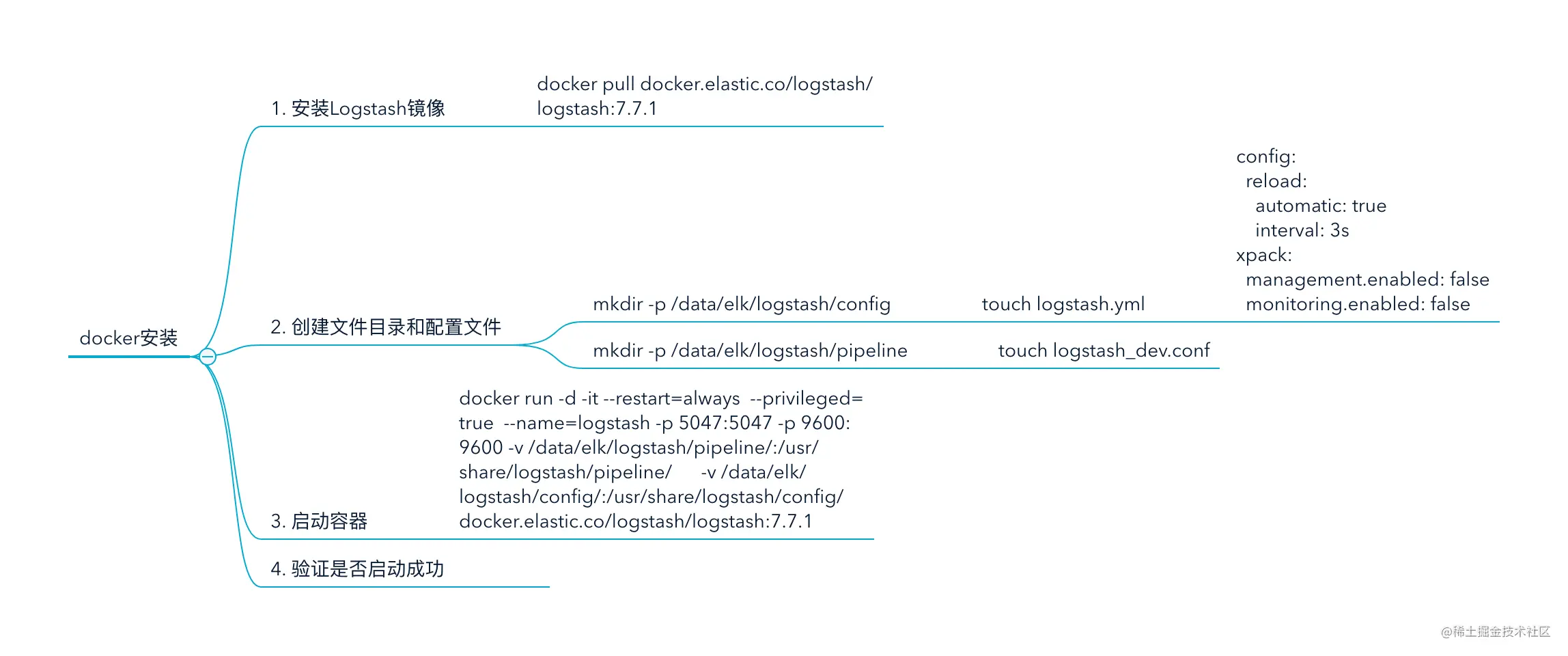
部署 logstash 日志收集工具 #
logstash的部署方式有很多种,一般情况下我们可以采用下载 logstash 安装包的方式去启动。
但是官方为我们提供了Docker的部署方式,我比较倾向于利用Docker来进行管理。
安装Logstash镜像
docker pull docker.elastic.co/logstash/logstash:7.7.1 复制代码
创建文件目录和配置文件
创建文件夹 #
mkdir -p /data/elk/logstash/config
mkdir -p /data/elk/logstash/pipeline
复制代码
创建配置文件 #
logstash.yml 放在/data/elk/logstash/config
touch logstash.yml
vi logstash.yml
config:
reload:
automatic: true
interval: 3s
xpack:
management.enabled: false
monitoring.enabled: false
复制代码
配置文件 pipelines.yml
放在/data/elk/logstash/config
在这里我们可以配置多个管道信息,来收集不同的信息
touch pipelines.yml
vi pipelines.yml
- pipeline.id: logstash_dev
path.config: /usr/share/logstash/pipeline/logstash_dev.conf
复制代码
配置文件 logstash_dev.conf
放在/data/elk/logstash/pipeline下
touch logstash_dev.conf
vi logstash_dev.conf
input {
beats {
port => 9900
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
mutate {
convert => {
"bytes" => "integer"
}
}
geoip {
source => "clientip"
}
useragent {
source => "user_agent"
target => "useragent"
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output {
stdout { }
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "xiaoguo_test_example"
}
}
复制代码
注意了,在这里我们可以配置索引的名称,以方便我们后面在查看
- 启动容器
最重要的一个环节来了,成败在此一举
docker run -d -it --restart=always --privileged=true --name=logstash -p 5047:5047 -p 9600:9600 -v /data/elk/logstash/pipeline/:/usr/share/logstash/pipeline/ -v /data/elk/logstash/config/:/usr/share/logstash/config/ docker.elastic.co/logstash/logstash:7.7.1
复制代码
指令可能存在换行的问题,可以先复制出来去掉换行
启动结果:

- 验证是否启动成功
通过docker logs id 来看logstash是否启动成功
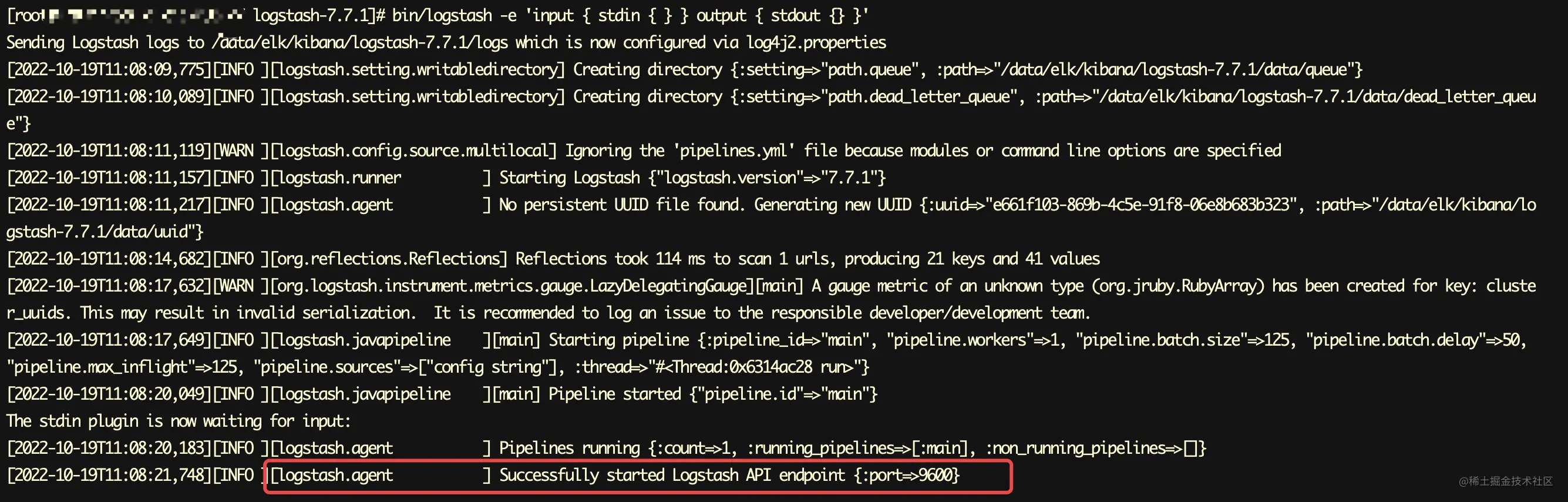
看到Successfully就表示成功了
- 修改 filebeat 配置文件
在前面的文章中我们已经将FlieBeat + Es + Kibana 的合并操作
我们只需要修改 filebeat 配置文件 filebeat.yml
将输出地址更改为我们部署的 logstash 地址
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/share/filebeat/logs/*
output.logstash:
hosts: ["ip:9900"]
复制代码
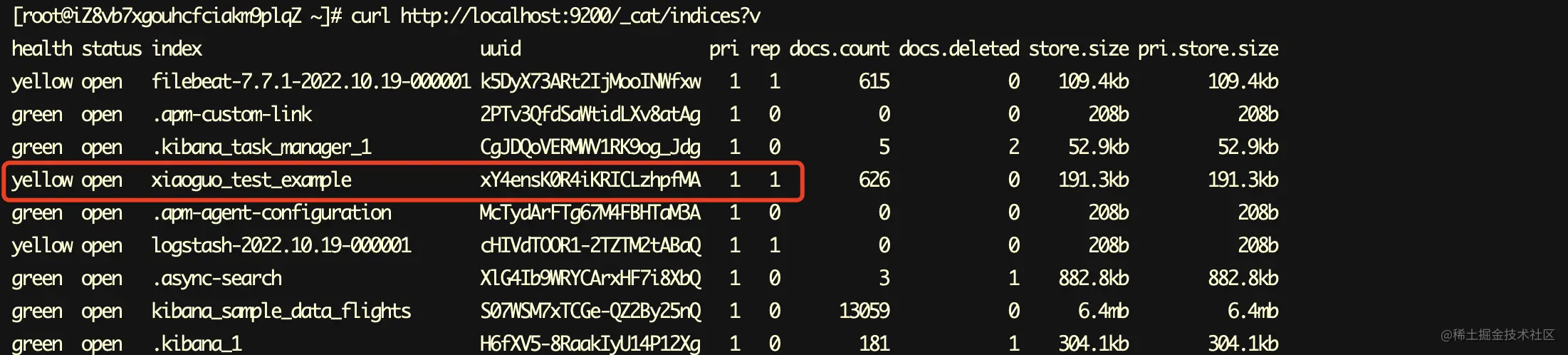
查询是否生成索引
curl http://localhost:9200/_cat/indices?v 复制代码
看到自定义名称的那个索引,就表示成功了
- 上Kibana查看
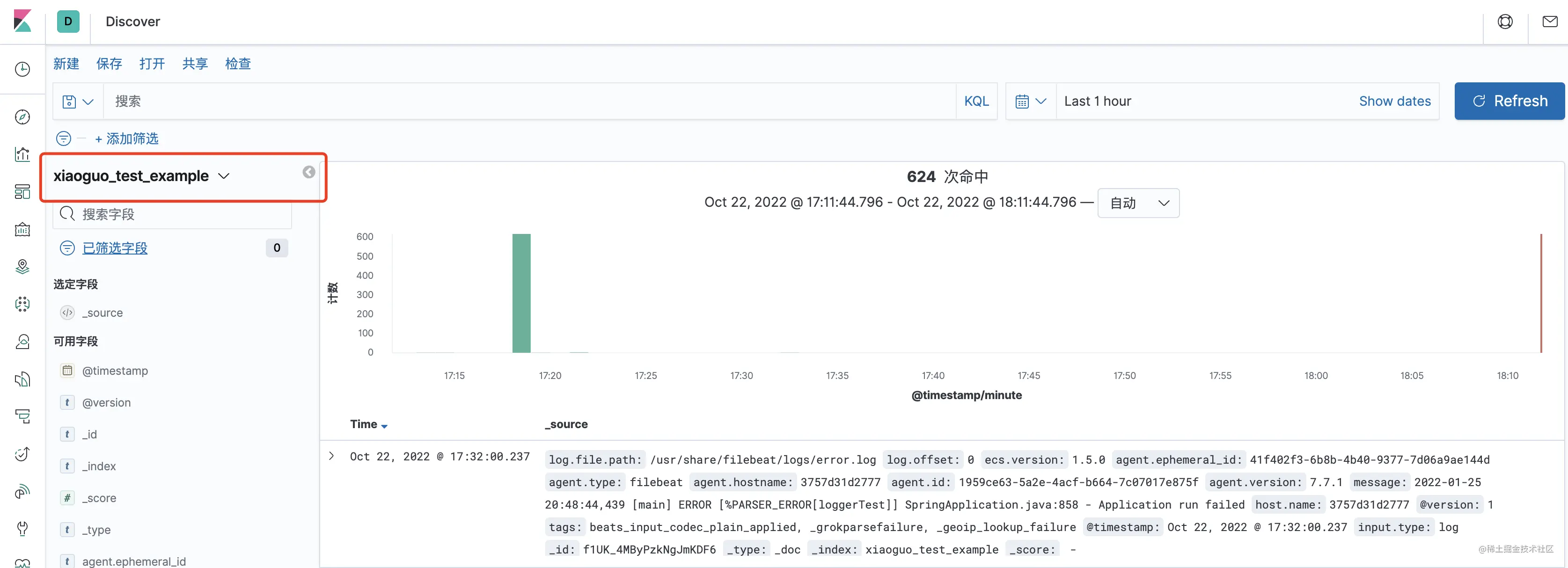
总结 #
我们主要完成在Docker环境下部署 logstash 日志收集工具,他是搭建ELK日志非常重要的一部分,上一篇文章Filebeat日志收集完成之后,将数据写入 Elasticsearch 后用 Kibana 进行可视化展示,现在我们已经完成了
Filebeat 收集数据写入 logstash处理,再将数据写入 Elasticsearch 后 Kibana 进行可视化展示的全过程。
转载说明 #
本文转载自《不得不学!从零到一搭建ELK日志,在Docker环境下部署 logstash 工具 - 掘金 (juejin.cn) (opens new window)》